
Chris 最早接觸 Elasticsearch 的時候版本還是 2.x 版(現在已經6.1.2版了),那個時候對於這套產品有點不以為意,因為之前做的專案,資料庫使用 RDBMS(關聯式資料庫管理系統)就能滿足大部分客戶的需求,不過最近因為某個專案需要開發日誌收集管理系統,survey 了一下後才發現 Elasticsearch 原來是那麼的強大,而且很符合專案需求的,於是開始比較深入了解 Elasticsearch 這套系統,而在這學習過程中 Chris 希望藉由著記錄,幫助自己與初次接觸 Elasticsearch 的新手了解運作原理、安裝過程、使用方法與自己有遇到的問題。
什麼是 Elasticsearch?
Elasticsearch (簡稱 ES) 是由荷蘭開發者 Shay Banon 所創造之開源分散式搜尋分析系統,Elasticsearch 不僅是一個資料庫,還是一個 base on Apache Lucene 為基礎建置的開放原始碼、分散式、RESTful 資訊檢索架構,由於 Elasticsearch 容易學習與架設,且同時具有很高的可擴充性 (scalability) 與可用性 (availability),以及極強的資料處理效能,所以 Elasticsearch 在最近幾年迅速崛起,成為機器學習分析,或即時日誌處理領域開源界的第一選擇。
什麼是 ELK?

Chris 剛接觸 Elasticsearch 的時候,買了幾本有關於 Elasticsearch 的書也爬了不少的文章,常常會看到有人會用 ELK 或 ELK Stack 這個詞,於是 Chris 立馬來 Google 一下什麼是 ELK,搜尋出來的結果有點讓我出乎意料 XD,第一名竟然是加拿大馬鹿!? 後來才知道原來 ELK Stack 是指 Elasticsearch、Logstash 和 Kibana 這三個 Open Source 軟體的集合套件,不過 Elasticsearch 在 5.0 版本加入 Beats 套件後就改成了 Elastic Stack 了,以下為各產品的簡單說明:
- Elasticsearch:核心資料庫是 NOSQL 的一種,但跟一般 NOSQL 的資料庫比較不一樣的地方,Elasticsearch 是透過 JSON 的方式來進行所有的 CRUD(select、insert、update、delete) 操作與設定
- Logstash:支援 48 種以上不同的輸入來源,及 50 種以上的輸出種類,可幫助你去收集各式各樣的 Log 或是資訊,並且根據你的 Log 來 Parser 成你要的資料欄位
- Kibana:視覺化與圖形化的方式來顯示各種 Log,可以透過 Elasticsearch 資料庫建立很多很漂亮的儀表板
- Beats:針對特定要收集的 Log,官方量身定做的輕量級日誌收集與轉送套件,目前的 Beats 有Filebeat、Packetbeat、Winlogbeat、Metricbeat、Heartbeat、Auditbeat 等,跟 Logstash 功能差不多,但只能單純的轉送 Log 無法像 Logstash 一樣自訂 Parser
了解了以上產品後,再來看圖才會比較有感覺,Elastic Stack 的架構大概會是長這樣:
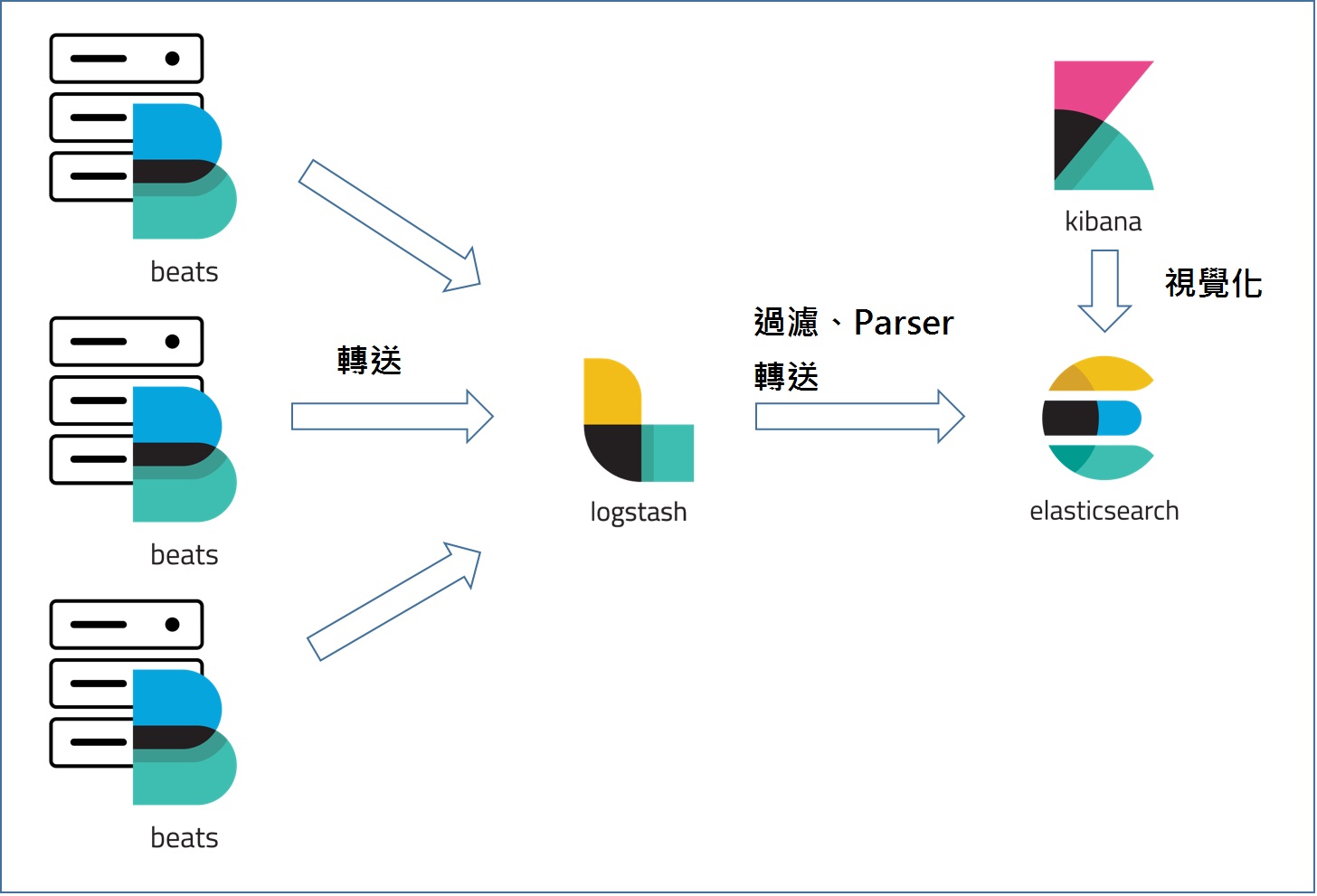
透過輕量級日誌收集與轉送套件 Beats,將所收集到的 Log 往 Logstash 上丟,Logstash 收到後會將這些 Log 進行過濾或 Parser,並將所有 Parser 過後的 Log 丟給 Elasticsearch 進行儲存,而 Kibana 就是讀取 Elasticsearch 資料庫裡的資料,將這些資料給圖形化。
名詞釋疑(關聯式資料庫與 ElasticSearch 名稱對應)
由於 Elasticsearch 和一般 RDBMS 架構不同,所以在名詞上也不太一樣,Chris 本身是 RDBMS 起家的,所以卡了一段時間才了解那些詞的意思,和 RDBMS 比照的話大概是這樣:
RDBMS
|
ElasticSearch
|
Server
|
Node
|
DB
|
Index
|
Table
|
Type
|
Primary key
|
Id
|
Row
|
Document
|
Column
|
Field
|
Schema
|
Mapping
|
Elasticsearch 運作機制

叢集(Cluster)/節點(Node)
在 Elasticsearch 系統架構中可以由多個具有同樣 cluster.name 節點(Node)來組成一個叢集(Cluster),其中有一個為主節點(如上圖中的★ ),因為 Elasticsearch 設計是一個去中心化的架構,也就是說節點(Node)之間是對等關係,每個節點(Node)上的資料都是即時同步的,如果主節點(Master)發生故障,會透過動態選舉的方式,將其中一台節點(Node)變成新的主節點(Master),而主節點只不過多了維護叢集(Cluster)狀態的功能,所以在 Elasticsearch 系統架構中比較不會有單點故障導致整個系統都 Crash 的問題。
分片(Shards)
從上圖來說,綠色一塊一塊的 0~4 代表索引分片,Elasticsearch 可以把一個完整的索引分成多個分片,這樣的好處是可以把一個大的索引拆分成多個,分散到不同的節點上,可以提升寫入效能及加速運算。另外分片的數量只能在索引建立前指定,並且索引建立後就不能更改。
副本(Replicas)
- 提高系統的容錯性(fail-over),當某個節點(Node)某個分片損壞或丟失時可以從副本中恢復
- 提升搜尋效能,Elasticsearch 會自動對搜尋請求進行負載平衡
elk-02存了:0、1、3、4 的分片
elk-03存了:0、2、3 的分片
elk-04存了:1、2、4 的分片
也就是說今天某一個節點(Node) 掛掉了,也不會影響資料喔。
Recovery
當有節點加入、退出叢集(Cluster)或故障節點重新啟動時,Elasticsearch 會根據各節點(Node)的負載情況,對索引分片(Shards)進行重新分配。
Discovery.zen
Discovery.zen 為 Elasticsearch 的自動發現節點(Node)機制,以及主節點(Master)的選舉。
小結
最後為什麼 Chris 會這麼推薦 Elasticsearch 這個軟體,除了查詢速度都是毫秒級可以完成外,最棒的是它的叢集能力(簡易擴充+高可用),這種去中心化的架構,不需要額外安裝一台 Master 或 Controller 去管理,每個節點(Node)都有機會遴選為主節點(Master),只要設好節點間 Discovery 的機制後,節點(Ndoe)之間的主機就會自行管理,大大降低了管理上的難度。如果對 Elasticsearch 核心的分散式運作機制有興趣可以參考:Elastic Stack and Product Documentation


![[Blogger] 如何在側欄新增「最新留言」的外掛小工具Widget](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhjrr3q5UHQf-QqriSE27-Z9qioWap7N0o0jNeK5y4aruATKIGYe318olp7KP_eyKl-odhD6GQZEH-TTu_6-sILCcgtws1DyKkEQWxCUB0hPscyjgX0nzDvuKFaQerdv1bYFpBc9_qbhOE/s72-c/904d36428256b3f9b38ce41c901ef6e8-706012.png)

![Logstash 無法丟 log 到 Elasticsearch 解決 The [default] mapping cannot be updated on index 問題](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgNVDy8FHj7JDEjg3OYINkH-Ng0Z1jEicFO8BYRVXW6yPJ1Fo2DDkPBICZSMiqWt2W7wCZajJ5BXQCHfLo6Z7p2euWJMTpDHxVX_g7yoHxMyvwxW7TL2B9ZKVte7E77F0LU6K5dlF-o3AIa/s72-c/c7c592bc71b5baf9c3661ee839eb28cf-766960.png)
沒有留言:
張貼留言